二叉树
二叉树(binary tree)是一种非线性数据结构,代表“祖先”与“后代”之间的派生关系,体现了“一分为二”的分治逻辑。与链表类似,二叉树的基本单元是节点,每个节点包含值、左子节点引用和右子节点引用。
js
/* 二叉树节点类 */
class TreeNode {
val; // 节点值
left; // 左子节点指针
right; // 右子节点指针
constructor(val, left, right) {
this.val = val === undefined ? 0 : val;
this.left = left === undefined ? null : left;
this.right = right === undefined ? null : right;
}
}每个节点都有两个引用(指针),分别指向左子节点(left-child node)和右子节点(right-child node),该节点被称为这两个子节点的父节点(parent node)。当给定一个二叉树的节点时,我们将该节点的左子节点及其以下节点形成的树称为该节点的左子树(left subtree),同理可得右子树(right subtree)。
在二叉树中,除叶节点外,其他所有节点都包含子节点和非空子树。
常见术语
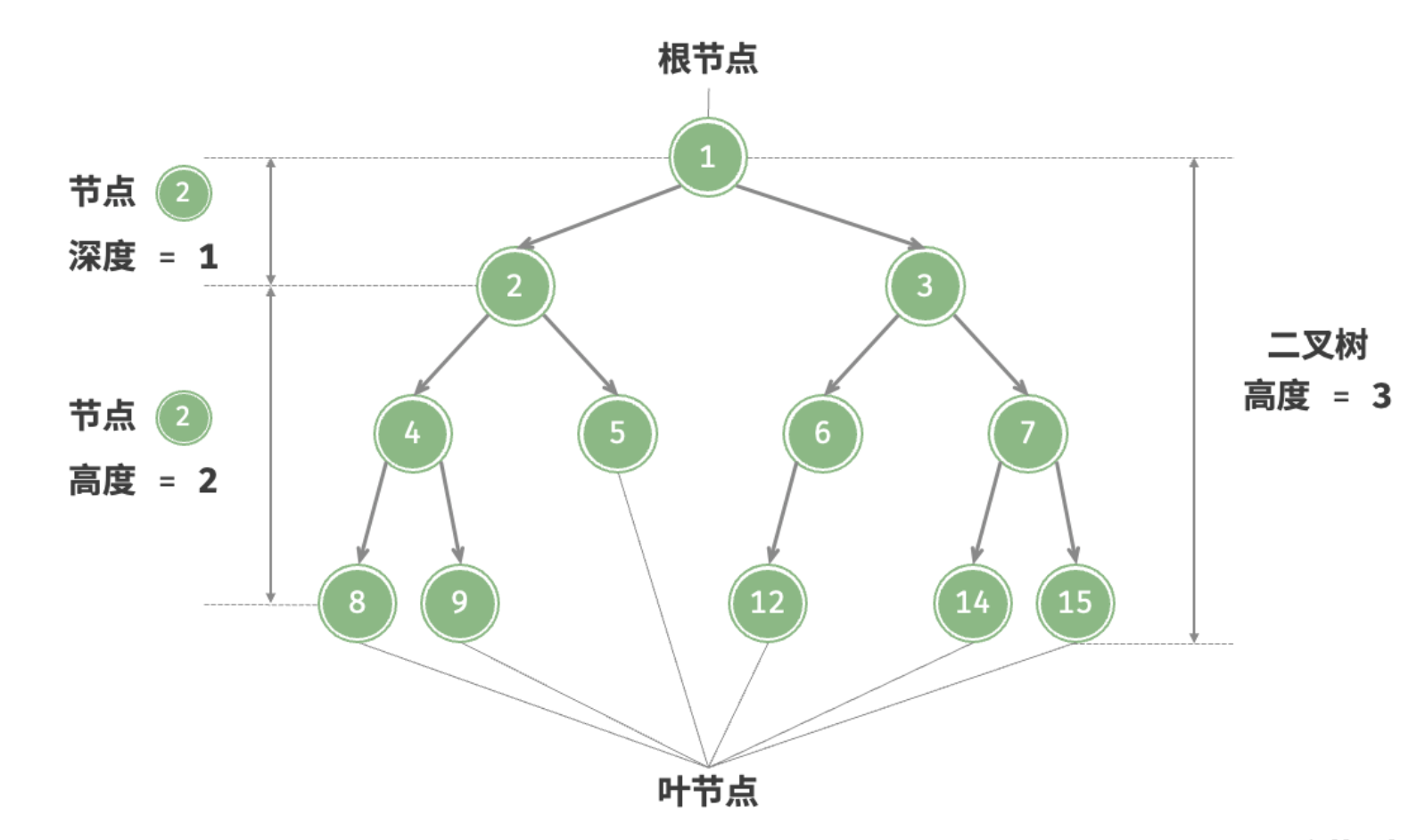
- 根节点(root node):位于二叉树顶层的节点,没有父节点。
- 叶节点(leaf node):没有子节点的节点,其两个指针均指向
None。 - 边(edge):连接两个节点的线段,即节点引用(指针)。
- 节点所在的层(level):从顶至底递增,根节点所在层为 1 。
- 节点的度(degree):节点的子节点的数量。在二叉树中,度的取值范围是 0、1、2 。
- 二叉树的高度(height):从根节点到最远叶节点所经过的边的数量。
- 节点的深度(depth):从根节点到该节点所经过的边的数量。
- 节点的高度(height):从距离该节点最远的叶节点到该节点所经过的边的数量。
TIP
我们通常将“高度”和“深度”定义为“经过的边的数量”,但有些题目或教材可能会将其定义为“经过的节点的数量”。在这种情况下,高度和深度都需要加 1 。
基本操作
初始化
首先初始化节点,然后构建引用(指针)。
js
/* 初始化二叉树 */
// 初始化节点
let n1 = new TreeNode(1),
n2 = new TreeNode(2),
n3 = new TreeNode(3),
n4 = new TreeNode(4),
n5 = new TreeNode(5);
// 构建节点之间的引用(指针)
n1.left = n2;
n1.right = n3;
n2.left = n4;
n2.right = n5;插入与删除节点
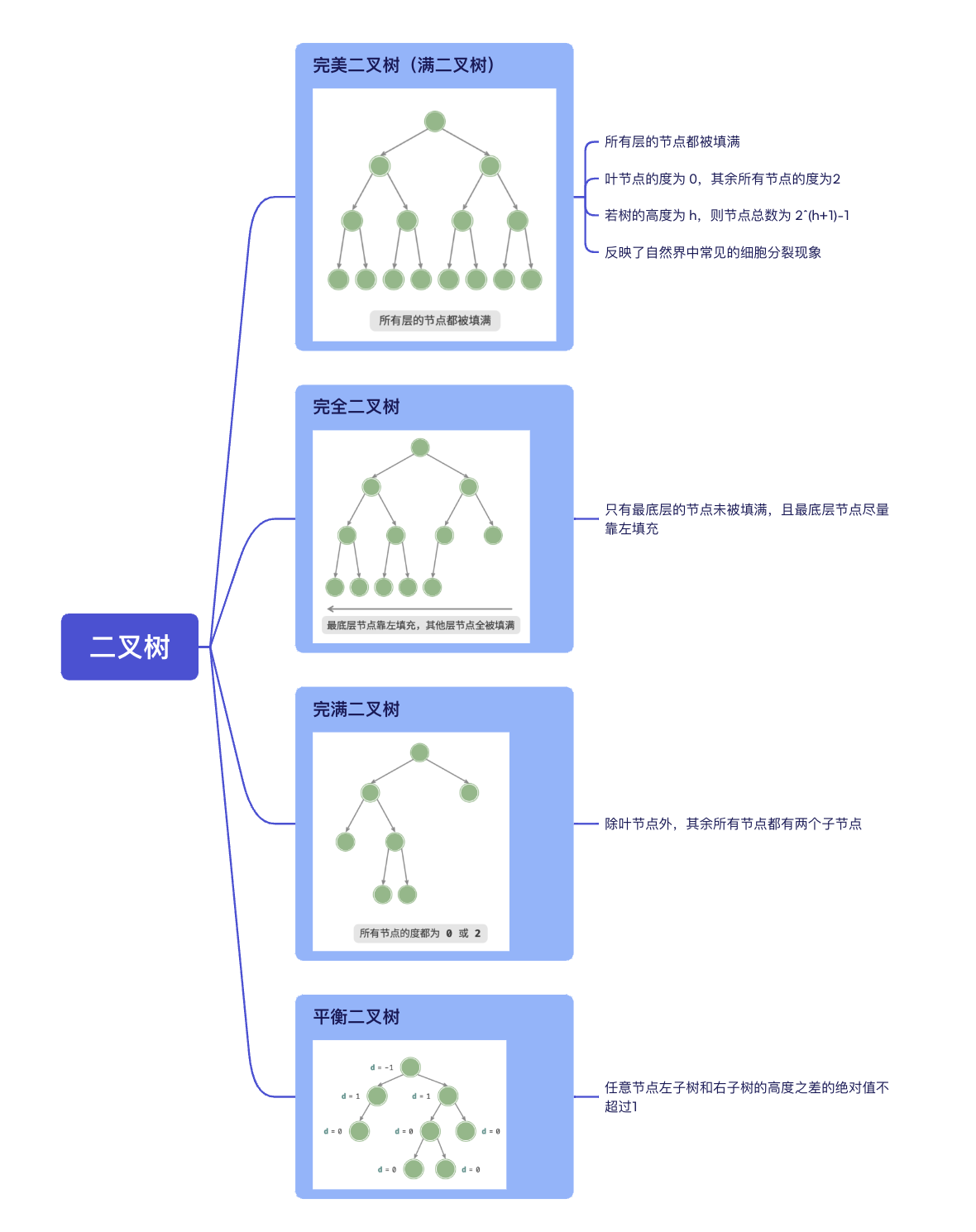
常见二叉树类型
- 完美二叉树
- 完全二叉树
- 完满二叉树
- 平衡二叉树
二叉搜索树
二叉搜索树也称二叉查找树,是指一颗空树或具有以下性质的二叉树:
- 若任意节点的左子树不空,则左子树上的所有节点的值均小于它的根节点的值;
- 若任意节点的右子树不空,则右子树上的所有节点的值均大于它的根节点的值;
- 任意节点的左右子树也分别为二叉查找树。
特点:
- 中序遍历一个二叉搜索树可以得到一个有序序列。
二叉树的退化
下图展现了二叉树的理想结构与退化结构。当二叉树的每层节点都被填满时,达到“完美二叉树”;当所有节点都偏向一侧时,二叉树退化为链表。
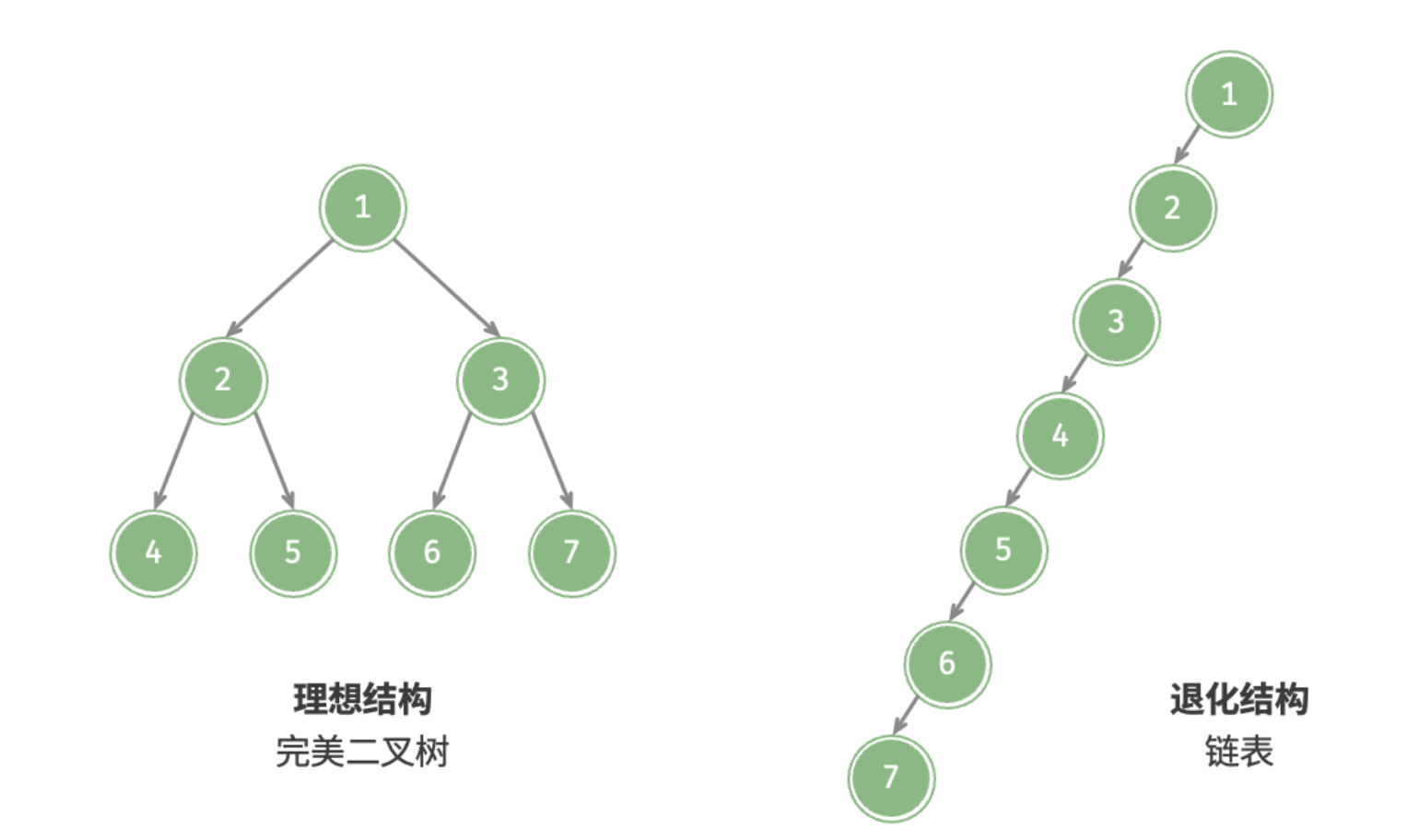
在最佳结构和最差结构下,二叉树的叶节点数量、节点总数、高度等达到极大值或极小值。
